




XPath Nedir?
İçindekiler
XPath (XML Path Language), XML dokümanlarındaki belirli bir öğeyi veya öğe kümesini bulmak için kullanılır. Özellikle XML tabanlı dokümanları inceleyebilmemizi, üzerinde işlem yapabilmemizi ve aradığımız bilgilere kolayca ulaşabilmemizi sağlayan bir kılavuz görevi görür. Yalnız XML değil HTML içerisinde de ihtiyacımız olan tüm verileri bize sunar. Bu içerikte XPath türlerinden, kavramlarından ve SEO için neden gerekli olduğundan bahsederek Screaming Frog’da Xpath ayarları yapılandırmasını anlatacağım. Aynı zamanda Google Sheets (E- Tablolar) ile kullanılabilecek kodlar listesine yazının devamında erişebileceksiniz. Böylece veri kazıma konusunda bilgi sahibi olacak ve SEO çalışmalarınızı daha sağlıklı bir şekilde yürütebileceksiniz.
XPath Türleri Nelerdir?
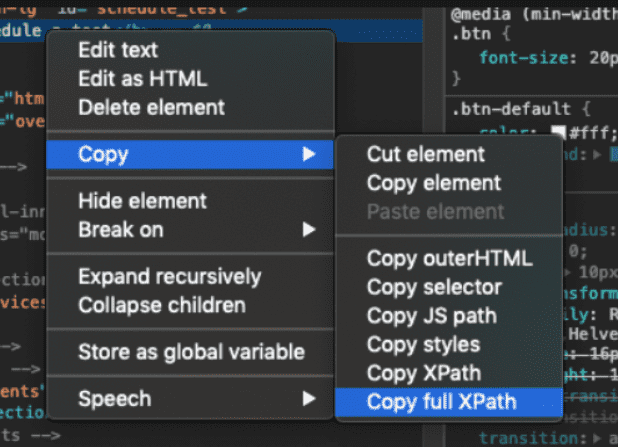
Absolute XPath
Absolute, bir öğeyi doğrudan bulabilmenizi sağlar. Devtools ile almak istediğiniz veriye copy full xpath ile ulaşabilirsiniz. Absolute için dikkat etmeniz gereken nokta, alacağınız verinin web sitesi üzerinde değişmeyecek olmasıdır. Değişme durumunda veri yolunu güncellemeniz gerekecektir. Güncelleme yapılmadan olan bir değişiklik durumunda işleminiz başarısız olur.
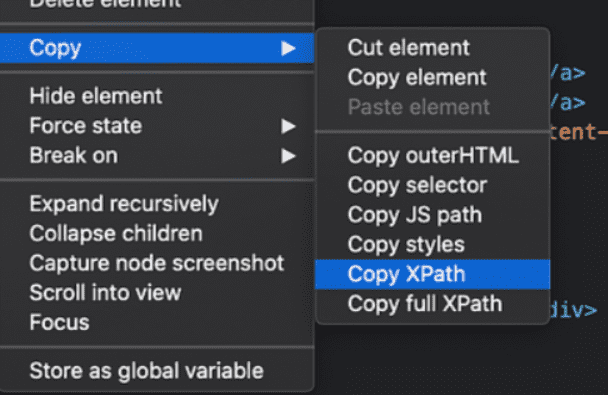
Relative XPath
Relative, DOM içerisinde istediğiniz veriyi tümüyle aramanızı sağlar. Web site içerisinde oluşabilecek bir değişiklik için öğeyi test ederken genelde relative Xpath kullanılır. Devtools üzerinden Copy > Copy XPath ile dilediğiniz verinin bilgisine kolayca ulaşabilirsiniz.
XPath'in Temel Kavramları
Düğüm (Node)
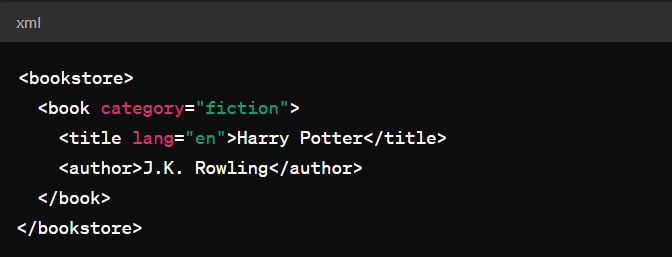
Yukarıda bir XML örneği verilmektedir. XML belgesi içerisinde yer alan her parça düğüm (node) olarak nitelendirilir. Yukarıdaki XML’de <bookstore>, <book>, <title>, <author> düğümleri bulunur.
Attribute
Yukarıdaki örnekte yer alan lang etiketinde olduğu gibi, XML dokümanı içerisinde yer alan düğümlerin class, id, href, lang gibi özelliklerine attribute adı verilir.
Parent
XML dokümanı içerisinde yer alan en üst düğüme parent (ebeveyn) adı verilir. Örnekte yer alan <bookstore>, parent’e örnektir.
Child
Parent içerisinde bulunurlar. Örnekte yer alan <title> elementi <book> elementinin child elementidir.
Sibling
Aynı ebeveyn düğümün altında bulunan düğümlere sibling (kardeş) düğümler denir. Örnekteki <title> ve <author> kardeş düğümlere örnektir.
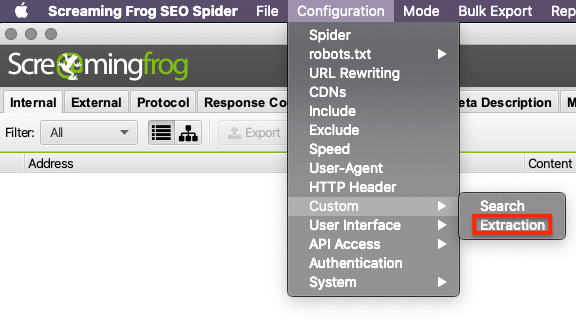
Screaming Frog’da XPath Ayarları Nasıl Yapılır?
Configuration > Custom > Extraction seçimini yapın.
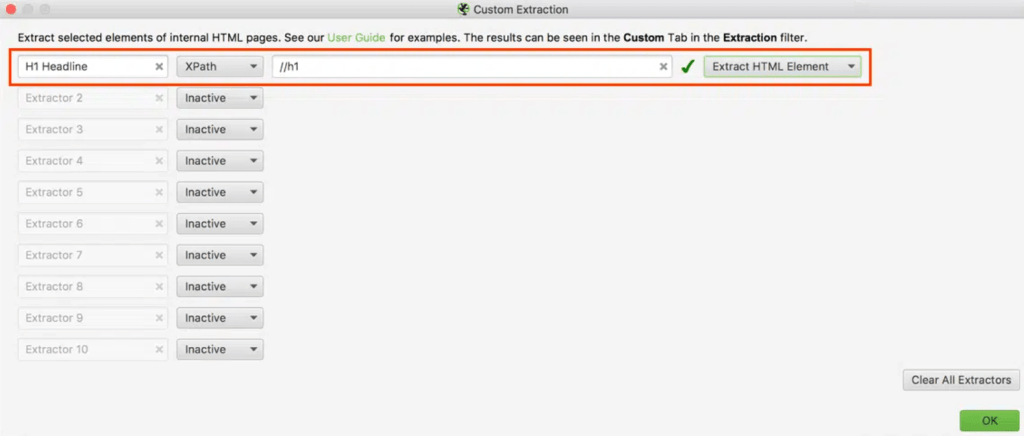
Açılan pencereden “Add” seçeneğine tıklayarak kopyaladığımız veriyi girip isim verebiliriz. Add butonu ile birden fazla veri ekleyebiliriz. Daha sonra “ok” butonuna basarak yaptığınız değişiklikleri kaydedin ve taramayı başlatın. Tarama işleminden sonra Custom Extraction sekmesinden XPath yolu ile taranan sayfaların verilerini görebilirsiniz.
Google Sheets ile Kullanılabilecek XPath Kodları Listesi
| Formül Adı | Formül | İşlev |
|---|---|---|
| Title | //title | Web sayfalarından title içeriğini çekmenizi sağlar. |
| H1 | //h1 | Web sayfalarından H1 içeriğini çekmenizi sağlar. |
| H2 | //h2 | Web sayfalarından H2 içeriğini çekmenizi sağlar. |
| H3 | //h3 | Web sayfalarından H3 içeriğini çekmenizi sağlar. |
| H4 | //h4 | Web sayfalarından H4 içeriğini çekmenizi sağlar. |
| H5 | //h5 | Web sayfalarından H5 içeriğini çekmenizi sağlar. |
| H6 | //h6 | Web sayfalarından H6 içeriğini çekmenizi sağlar. |
| Meta Description | /html/head/meta[@name=”description”]/@content | Web sayfalarından meta açıklama içeriğini çekmenizi sağlar. |
| Canonical | /html/head/link[@rel=”canonical”]/@href | Web sayfalarınn canonical etiketini çekmenizi sağlar. |
| Index | /html/head/meta[@name=”robots”]/@content | Web sayfalarının index durumunu görmenizi sağlar. |
| Görsel Sayısı | count(//img) | Web sayfalarının toplam görsel sayısını gösterir. |
| Alt Etiket | //img/@alt | Web sayfalarındaki tüm görsellerin tüm alt etiket içeriklerini gösterir. |
| Alt Etiket Sayısı | count(//img/@alt) | Web sayfalarında yer alan tüm görsellerin alt etiket sayılarını gösterir. |
| Linkler | //a/@href | Web sayfalarında yer alan tüm linkleri gösterir. |
| Link Sayısı | count(//a/@href) | Web sayfalarında yer alan tüm linklerin sayısını görmenizi sağlar. |
| Sitemap | //*[local-name() =’sitemap’]/*[local-name() =’loc’] | Sitemap dizinleri içerisinde yer alan alt site haritalarını görmenizi sağlar. |
| Sitemap 2 | //*[local-name() =’url’]/*[local-name() =’loc’] | Özel belirttiğiniz sitemap URL’leri içerisinde yer alan linkleri görmenizi sağlar. |
| Hreflang | //@lang | Web sayfalarının dil etiketini görmenizi sağlar. |
Google E-Tablolar ve XPath ile Veri Kazıma
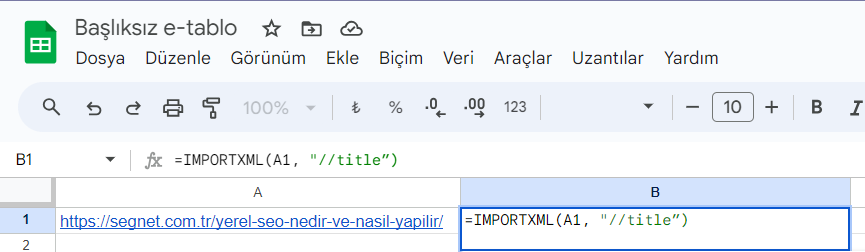
Yukarıdaki örnekte SegNet sitesi içerisinden Yerel SEO Nedir ve Nasıl Yapılır? Başlıklı blog yazısının URL’ini A1 hücresine yapıştırdım. Siz kendi seçmek istediğiniz URL’i girin ve yan hücresine, tırnak işaretlerine dikkat ederek formülü tabloya geçirin. XPath sorgusu yeşile döndüğünde doğru yolda olduğunuzu anlayacaksınız. Son olarak enter’a basın ve E-tablo otomatik olarak sayfanın başlığını çekecektir. Dilediğiniz URL’i A sütununa sıralı olarak ekledikten sonra başlıklarını yan sütunda görebilirsiniz. Tekrardan her bir URL için fonksiyon yazmanıza gerek yok. Yapmanız gereken formülün olduğunu hücreyi işaretleyerek sağ altındaki kareye çift tıklamaktır. Çekmeyi planladığınız verinin JavaScript ile modifiye edilmemiş olmasına ve çok fazla URL olmamasına özen gösterin.
XPath ve SEO İlişkisi
XPath’in öğrenimi ve kullanımı diğer dillere göre oldukça kolaydır. SEO için kritik bir öneme sahiptir. SEO çalışmalarınızda verilere erişmek, sitenizi analiz etmek ve hatalarınızı tespit etmek gibi birçok alanda size fayda sağlayabilir. Örneğin başlık etiketleri, meta açıklamaları ve URL yapıları gibi belirli öğeleri belirlemek için kullanılabilir. Ayrıca, belirli anahtar kelimelerin içeriğe ne kadar uygun bir şekilde dağıtıldığını ve anahtar kelimelerin kullanım sıklığını analiz edebilirsiniz. Sitenizi teknik ve içerik anlamında optimize ederek site performansınızı yükseltmeniz mümkündür. Bu, içeriğinizi optimize etmek ve arama motorlarında daha iyi sıralama elde etmek için oldukça faydalı bir yöntemdir.


